Die 8. „Force Unleashing Cloud Native Observability Sharing Session“ von Spruce Network R&D VP Xiang Yang teilte „DeepFlow – Opening a New Era of Highly Automated Observability“ , die erste Open-Source-Version von DeepFlow wurde offiziell veröffentlicht , es ist eine hochgradig automatisierte Observability-Plattform kann den Aufwand für das Vergraben, Codieren und die Wartung für Entwickler erheblich reduzieren.
Klicken Sie auf die Karte unten, um die Videowiedergabe anzusehen.
 Bilibili , Transaktionsgarantie , Kaufen Sie mit Vertrauen , DeepFlow
Bilibili , Transaktionsgarantie , Kaufen Sie mit Vertrauen , DeepFlow  - Miniprogramme , dieeine neue Ära
- Miniprogramme , dieeine neue Ära
Lernen Sie DeepFlow kennen
Hallo Freunde im Live-Übertragungsraum, ich freue mich sehr, die offizielle Veröffentlichung der ersten Open-Source-Version von DeepFlow mit Ihnen zu teilen. Ich glaube, dass durch meine heutige Einführung jeder eine neue Ära hochautomatisierter Beobachtbarkeit spüren kann, lassen Sie uns sie gemeinsam miterleben und eröffnen.
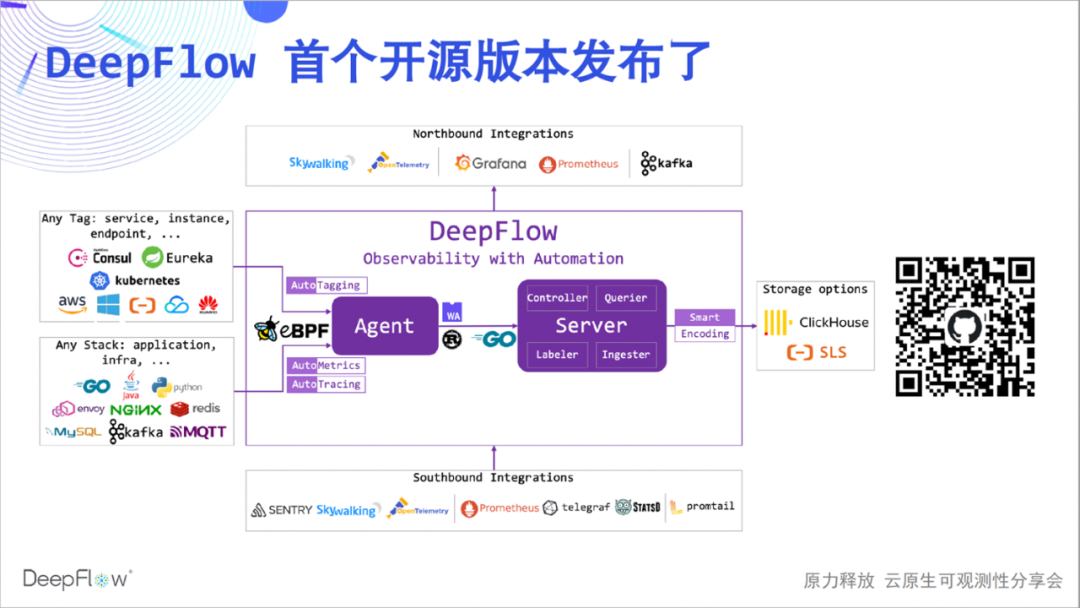
Das folgende ist das Architekturdiagramm der Community-Version von DeepFlow Einige Freunde wissen nicht viel über DeepFlow, also werde ich es kurz vorstellen. DeepFlow ist eine selbst entwickelte Observability-Plattform von Yunshan Network, die auf einer Reihe von Innovationen in eBPF und anderen Technologien basiert und hochgradig automatisiert ist, was den Arbeitsaufwand für Entwickler beim Aufbau von Observability erheblich reduziert.
Wir können sehen, dass es Ressourcen, Dienste und das benutzerdefinierte Label von K8 automatisch synchronisieren und als Label in Beobachtungsdaten einfügen kann (AutoTagging). Mechanismus reduziert den Verbrauch von Tag-Speicherressourcen um den Faktor 10. Darüber hinaus verfügt es über gute Integrationsfähigkeiten, kann eine Vielzahl von Datenquellen integrieren und bietet eine gute Northbound-Schnittstelle auf der Basis von SQL. Der Kern von DeepFlow ist Open Source basierend auf der Apache 2.0-Lizenz. Geben Sie uns gerne einen 🌟 Stern ( scannen Sie den QR-Code unten )!
Wenn wir über hohe Automatisierungsgrade sprechen, welche Botschaft versuchen wir zu vermitteln? Das heutige Teilen beginnt mit vier Aspekten:
-
Erstens führt es AutoMetrics ein, die automatische Indikatordatenerfassungsfunktion von DeepFlow, die automatisch die Beziehung zwischen Full-Stack-Leistungsindikatoren und Panoramadiensten anzeigt;
-
Als nächstes kommen die automatisierten Prometheus- und Telegraf-Integrationsfunktionen, die die vollständigsten Indikatordaten sammeln und das Problem von Datensilos und hoher Kardinalität lösen;
-
Danach nehme ich Sie mit zu AutoTracing, DeepFlows innovativer automatisierter verteilter Tracing-Funktion auf Basis von eBPF. Ich glaube, dass dies definitiv eine Weltklasse-Innovation ist;
-
Schließlich demonstrieren die automatisierten OpenTelemetry- und SkyWalking-Integrationsfunktionen erstaunliche verteilte Tracking-Funktionen ohne blinde Flecken und lösen den Schmerz unvollständiger Verfolgung.
Ein hoher Automatisierungsgrad kann es Entwicklern ermöglichen, mehr Zeit für die Geschäftsentwicklung aufzuwenden, und Teams können zusammenarbeiten, um Probleme reibungsloser zu lösen.
Werfen wir also einen Blick auf den ersten Aufzählungspunkt von heute, AutoMetrics.
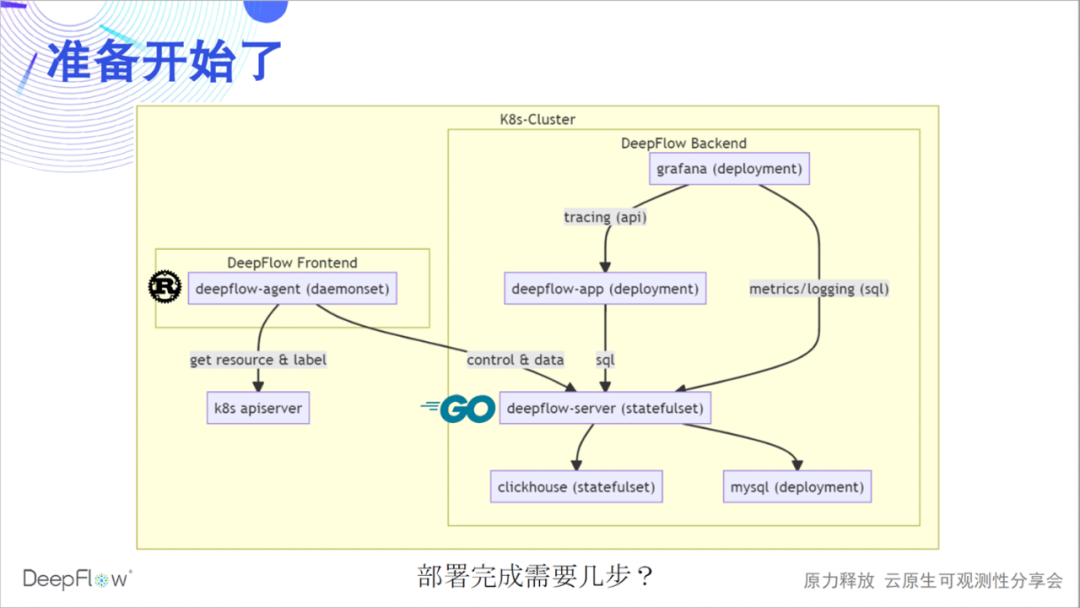
Lassen Sie uns aufwärmen und einen vollständigen Satz von DeepFlow bereitstellen. Die folgende Abbildung zeigt die Software-Architektur von DeepFlow deutlicher: Der von Rust implementierte Deepflow-Agent sammelt als Frontend Daten und synchronisiert Ressourcen und Label-Informationen mit dem K8s-Apiserver; der von Golang implementierte Deepflow-Server ist für Management, Steuerung, Last verantwortlich Freigabe und Speicherabfrage als Backend. . Wir verwenden MySQL zum Speichern von Metadaten, ClickHouse zum Speichern von Beobachtungen und zum Ersetzen von Erweiterungen und Grafana zum Anzeigen von Beobachtungen.
Derzeit haben wir auch einen Deepflow-App-Prozess in Python implementiert, um eine verteilte Tracing-API bereitzustellen, die in Golang neu geschrieben und schrittweise in Deepflow-Server integriert wird. deepflow-server bietet SQL-API aufwärts, auf deren Grundlage wir Grafanas DeepFlow DataSource und Panels wie Topologie und verteiltes Tracing entwickelt haben. deepflow-agent kann in der Host- oder K8s-Umgebung ausgeführt werden, aber deepflow-server muss in K8s ausgeführt werden. Lassen Sie uns raten, wie viele Schritte erforderlich sind, um DeepFlow in einem K8s-Cluster bereitzustellen?
Ja, es ist nur ein Schritt erforderlich. Kopieren Sie diese wenigen Helmnamen und fügen Sie sie ein, um die Bereitstellung abzuschließen. Wenn Sie einen Computer an Ihrer Seite haben, können Sie sich auf die Bereitstellungsdokumentation beziehen, um sie jetzt bereitzustellen, und sich darauf freuen, Feedback zur Bereitstellungserfahrung im Live-Übertragungsraum oder in unserer WeChat-Gruppe zu geben.
helm repo add deepflow https:helm repo update deepflowhelm install deepflow -n deepflow deepflow/deepflow --create-namespace
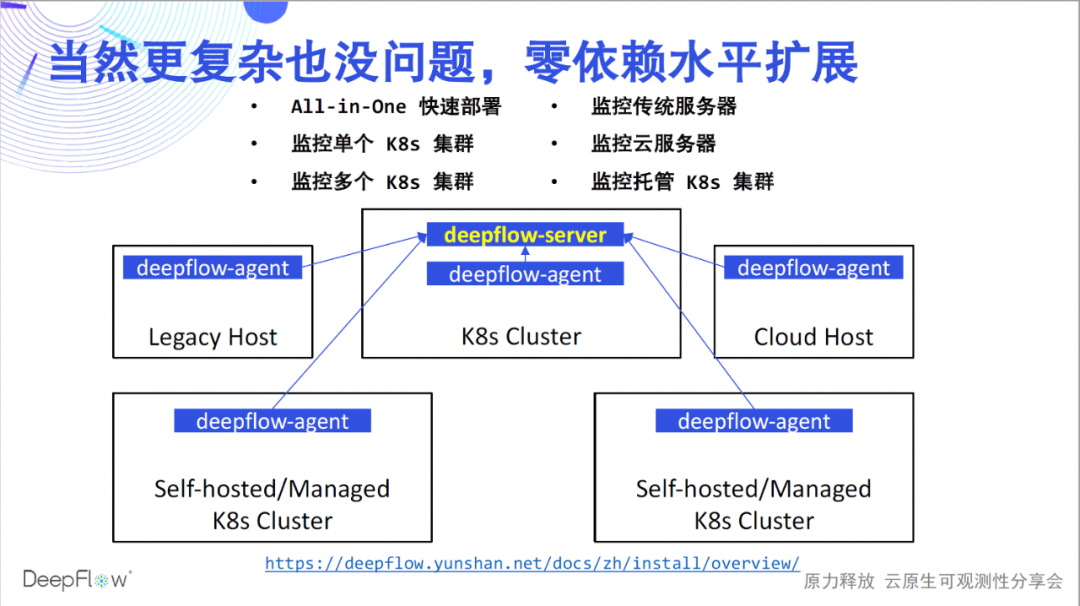
Der Einsatz löst jetzt nur das Monitoring-Problem eines K8s-Clusters, und die Fähigkeiten von DeepFlow sind natürlich nicht darauf beschränkt. Bezugnehmend auf die Bereitstellungsdokumentation kann DeepFlow problemlos in verschiedenen Szenarien bereitgestellt werden. Wir unterstützen ein schnelles All-in-One-Einzelknotenerlebnis; unterstützen die Überwachung mehrerer K8s-Cluster und fügen automatisch K8s-Ressourcen und benutzerdefinierte Label-Labels für alle Daten ein; unterstützen die Überwachung traditioneller Server und Cloud-Server und fügen automatisch Cloud-Ressourcen-Labels für alle Daten ein; schließlich Wir unterstützen auch die Überwachung verwalteter K8s-Cluster und fügen automatisch K8s- und Cloud-Ressourcen-Tags ein. In all diesen Szenarien kann DeepFlow horizontal skaliert werden, ohne auf externe Komponenten angewiesen zu sein. Nachdem die Bereitstellung nun abgeschlossen ist, können wir unsere Reise zur hochgradig automatisierten Beobachtbarkeit beginnen.
 Die goldenen Indikatoren, über die wir am häufigsten sprechen, sind im Allgemeinen die Anforderung, der Fehler und die Verzögerung des Dienstes. Die folgende Abbildung zeigt die ROTEN Indikatoren für die Anwendungsleistung aller Microservices, die nach der Bereitstellung von DeepFlow angezeigt werden können, unabhängig davon, in welcher Sprache es implementiert ist. Wir unterstützen derzeit die Erfassung von Metrikdaten für HTTP 1/2/S-, Dubbo-, MySQL-, Redis-, Kafka-, MQTT- und DNS-Anwendungen, und die Support-Liste wächst weiter. Wir fügen automatisch Dutzende oder sogar Hunderte von Dimensionsbezeichnungsfeldern für alle Indikatordaten ein, einschließlich Ressourcen, Dienstleistungen und benutzerdefinierten Bezeichnungen von K8s, wodurch Benutzer flexibel aggregieren und aufschlüsseln können. Aber hier möchten wir die Fähigkeit der Automatisierung betonen: Das Entwicklungsteam dieser Indikatoren muss sich nicht mehr um das Einfügen von Code kümmern, und das Betriebs- und Wartungsteam muss sich nicht mehr darum kümmern, die Entwicklung immer zum Einfügen von Code zu drängen. Die Automatisierung von DeepFlow macht jedes Team produktiver und die Teamarbeit harmonischer.
Die goldenen Indikatoren, über die wir am häufigsten sprechen, sind im Allgemeinen die Anforderung, der Fehler und die Verzögerung des Dienstes. Die folgende Abbildung zeigt die ROTEN Indikatoren für die Anwendungsleistung aller Microservices, die nach der Bereitstellung von DeepFlow angezeigt werden können, unabhängig davon, in welcher Sprache es implementiert ist. Wir unterstützen derzeit die Erfassung von Metrikdaten für HTTP 1/2/S-, Dubbo-, MySQL-, Redis-, Kafka-, MQTT- und DNS-Anwendungen, und die Support-Liste wächst weiter. Wir fügen automatisch Dutzende oder sogar Hunderte von Dimensionsbezeichnungsfeldern für alle Indikatordaten ein, einschließlich Ressourcen, Dienstleistungen und benutzerdefinierten Bezeichnungen von K8s, wodurch Benutzer flexibel aggregieren und aufschlüsseln können. Aber hier möchten wir die Fähigkeit der Automatisierung betonen: Das Entwicklungsteam dieser Indikatoren muss sich nicht mehr um das Einfügen von Code kümmern, und das Betriebs- und Wartungsteam muss sich nicht mehr darum kümmern, die Entwicklung immer zum Einfügen von Code zu drängen. Die Automatisierung von DeepFlow macht jedes Team produktiver und die Teamarbeit harmonischer.
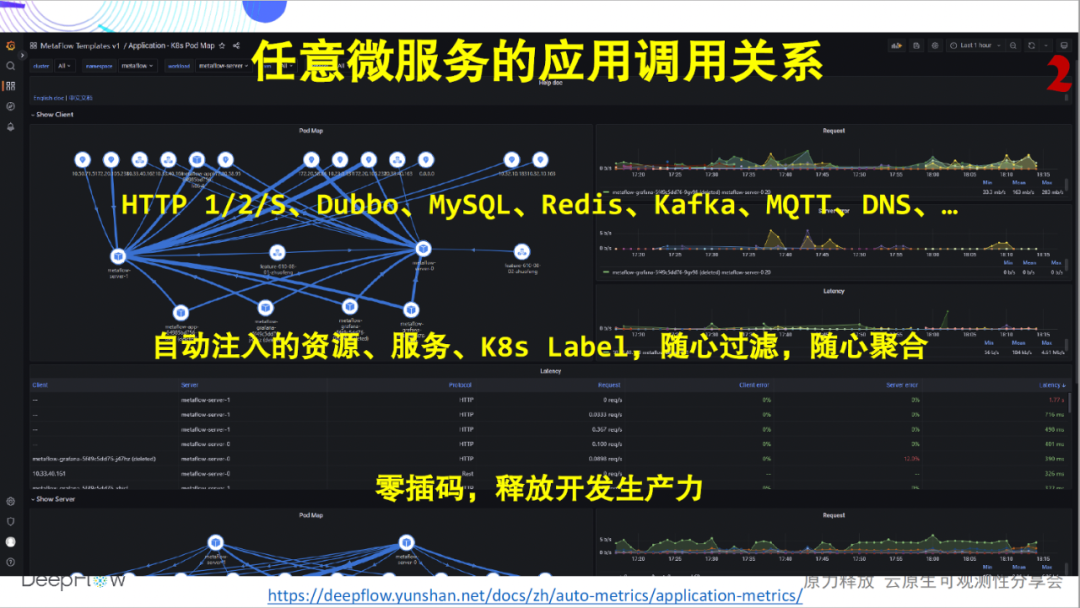
 Betrachtet man ein anderes Bild, kann DeepFlow zusätzlich zu einem einzelnen Dienst auch die Beziehung der Anwendungsaufrufe zwischen beliebigen Mikrodiensten darstellen. Wieder komplett Null-Interpolation. Über das Dokument können Sie sich in unsere Online-Demo-Umgebung einloggen, um praktische Erfahrungen zu sammeln.
Betrachtet man ein anderes Bild, kann DeepFlow zusätzlich zu einem einzelnen Dienst auch die Beziehung der Anwendungsaufrufe zwischen beliebigen Mikrodiensten darstellen. Wieder komplett Null-Interpolation. Über das Dokument können Sie sich in unsere Online-Demo-Umgebung einloggen, um praktische Erfahrungen zu sammeln.
Ist das alles, was dazu gehört? Viel mehr als das! In einer Cloud-nativen Umgebung nimmt die Komplexität des Netzwerks erheblich zu und wird zu einer Black Box für die Fehlerbehebung, und das Auffinden von Problemen ist normalerweise ein Rätselraten. DeepFlow verfügt über Full-Stack-Überwachungsfunktionen für die Anwendungsleistung und kann automatisch Hunderte von Indikatoren wie Durchsatz, Verbindungsaufbau-Ausnahme, Verbindungsaufbau-Verzögerung, Übertragungsverzögerung, Nullfenster, erneute Übertragung, Parallelität usw. von jedem Microservice erfassen .
In ähnlicher Weise kann DeepFlow auch die Netzwerkaufrufbeziehung zwischen beliebigen Microservices darstellen. Immer noch komplett Null-Interpolation.
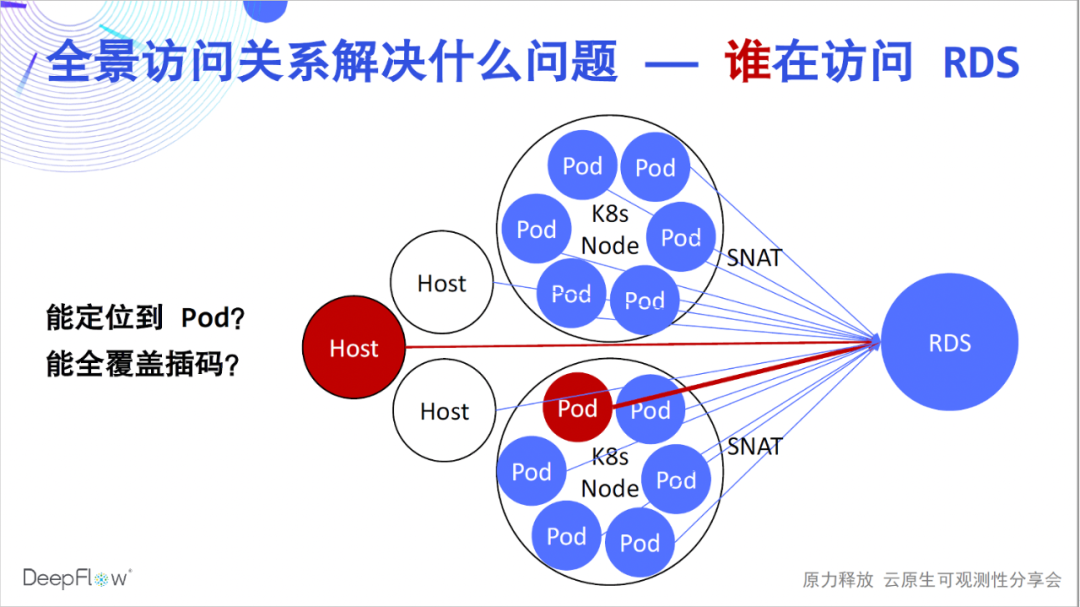
Nun, ich glaube, dass jeder begonnen hat, den Atem der Hochautomatisierung wirklicher zu spüren. Aber welche Probleme lösen sie? Durch die automatische Panorama-Zugriffsbeziehung können Kunden der DeepFlow Enterprise Edition schnell eine große Anzahl von Fehlerortungsproblemen lösen, wie z. B. RDS-Betrieb und -Wartung, die verwendet werden, um zu ermitteln, welcher Client die größte Zugriffslast verursacht hat. Aufgrund der Existenz von SNAT in der K8s-Umgebung gibt es keine Möglichkeit zu wissen, auf welche Pods zugegriffen wird. Bei der traditionellen Methode können wir nur Codes auf Client-Seite einfügen, aber es ist schwierig, eine umfassende Abdeckung zu erreichen. Das Lösen solcher Probleme mit DeepFlow ist ein Kinderspiel, durchsuchen Sie einfach das RDS, um Leistungsmetriken für alle Clients zu erhalten, die darauf zugreifen.
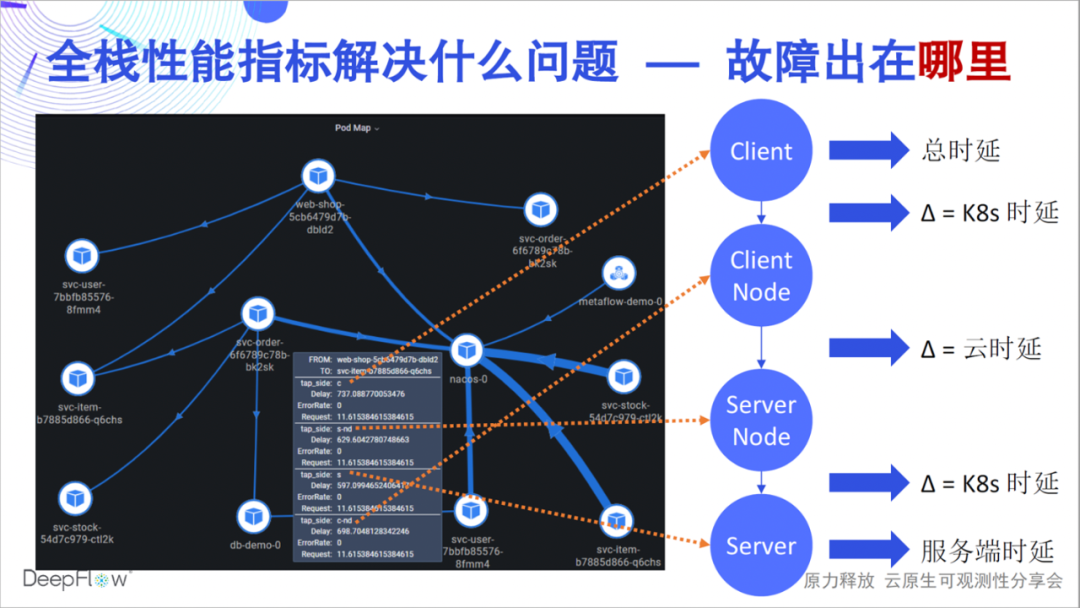
 Welche Probleme können Full-Stack-Leistungskennzahlen also lösen? Ein Fehler kann sein, dass die Latenz einer API zu hoch ist, aber welcher Link ist die Ursache für die Latenz, welches Team sollte dafür verantwortlich sein und wie schnell kann Ihr Team ein solches Problem lösen? Die Full-Stack-Fähigkeit von DeepFlow kann den Leistungsstatus einer Zugriffsbeziehung in jedem Schlüsselknoten schnell beantworten. Wie in dieser Abbildung gezeigt, können wir beispielsweise genau unterscheiden, ob der Engpass im Server-Pod, im Service-K8s-Netzwerk oder im Cloud-Netzwerk liegt , und Client K8s Das Netzwerk oder der Client selbst. DeepFlow macht die Fehlerbehebung in einer verteilten Umgebung so einfach wie eine einzelne Maschine und ist dennoch vollständig automatisiert.
Welche Probleme können Full-Stack-Leistungskennzahlen also lösen? Ein Fehler kann sein, dass die Latenz einer API zu hoch ist, aber welcher Link ist die Ursache für die Latenz, welches Team sollte dafür verantwortlich sein und wie schnell kann Ihr Team ein solches Problem lösen? Die Full-Stack-Fähigkeit von DeepFlow kann den Leistungsstatus einer Zugriffsbeziehung in jedem Schlüsselknoten schnell beantworten. Wie in dieser Abbildung gezeigt, können wir beispielsweise genau unterscheiden, ob der Engpass im Server-Pod, im Service-K8s-Netzwerk oder im Cloud-Netzwerk liegt , und Client K8s Das Netzwerk oder der Client selbst. DeepFlow macht die Fehlerbehebung in einer verteilten Umgebung so einfach wie eine einzelne Maschine und ist dennoch vollständig automatisiert.
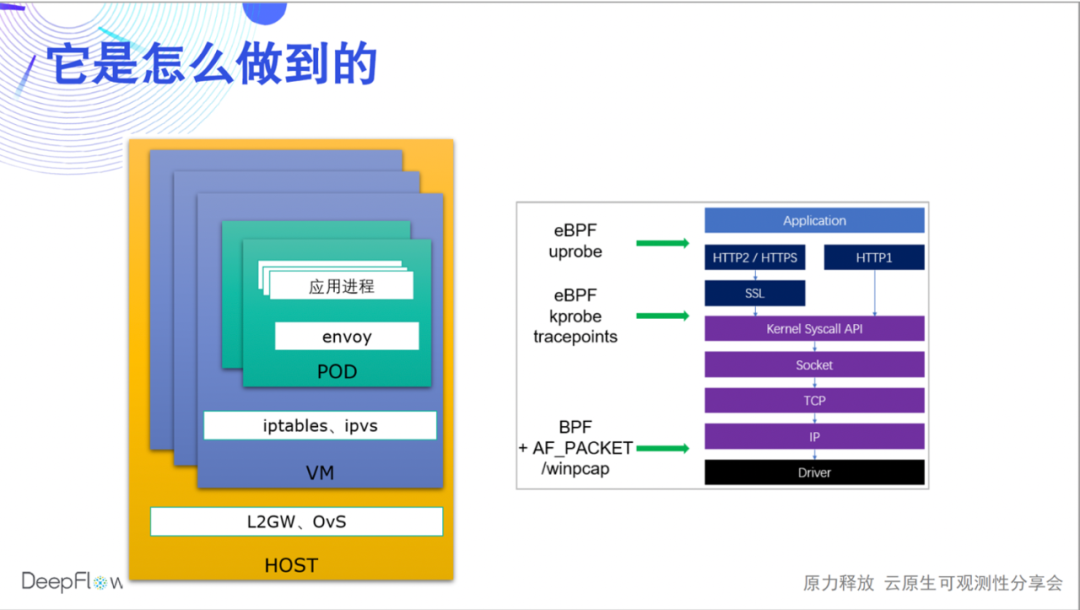
 Wie macht DeepFlow das? Heute können wir nur das Wasser berühren, und es wird weitere Live-Übertragungen und Artikel geben, um den zugrunde liegenden Mechanismus zu teilen. Wir verwenden eBPF und BPF, um die Leistungsdaten jeder Anfrage (Flow im Namen von DeepFlow) während der Anwendung, Systemaufrufe und Netzwerkübertragung zu sammeln und automatisch zuzuordnen. So können wir einerseits alle Kommunikationsendpunkte (Microservices) abdecken, andererseits können wir auch die Leistungsdaten jedes Hops korrelieren und das Problem im Anwendungsprozess, Sidecar, Pod virtual, schnell lokalisieren Netzwerkkarte und Knoten-Netzwerkkarte. , DeepFlow Enterprise Edition kann weiterhin Host-Netzwerkkarten, NFV-Gateway-Netzwerkkarten, physische Netzwerkelement-Ports usw. lokalisieren.
Wie macht DeepFlow das? Heute können wir nur das Wasser berühren, und es wird weitere Live-Übertragungen und Artikel geben, um den zugrunde liegenden Mechanismus zu teilen. Wir verwenden eBPF und BPF, um die Leistungsdaten jeder Anfrage (Flow im Namen von DeepFlow) während der Anwendung, Systemaufrufe und Netzwerkübertragung zu sammeln und automatisch zuzuordnen. So können wir einerseits alle Kommunikationsendpunkte (Microservices) abdecken, andererseits können wir auch die Leistungsdaten jedes Hops korrelieren und das Problem im Anwendungsprozess, Sidecar, Pod virtual, schnell lokalisieren Netzwerkkarte und Knoten-Netzwerkkarte. , DeepFlow Enterprise Edition kann weiterhin Host-Netzwerkkarten, NFV-Gateway-Netzwerkkarten, physische Netzwerkelement-Ports usw. lokalisieren.
 Es gibt noch viel Arbeit, um die Iteration fortzusetzen. Wir wissen, dass die Header-Felder von HTTP2/gRPC komprimiert sind. Derzeit unterstützen wir das Parsing von Protokoll-Headern basierend auf statischen Komprimierungstabellen. In Zukunft werden wir eBPF uprobe verwenden, um dynamische Komprimierungstabellen für das vollständige Header-Parsing zu erhalten. Für HTTPS unterstützen wir derzeit die Fähigkeit von eBPF uprobe, Golang-Anwendungen zu sammeln, und werden in Zukunft schrittweise C/C++/Java/Python und andere Sprachen unterstützen. Gleichzeitig verstehen wir auch, dass es in der tatsächlichen Geschäftsumgebung eine große Anzahl privater Anwendungsprotokolle geben wird, und wir hoffen, Entwicklern durch die WebAssembly-Technologie eine flexible Programmierbarkeit bieten zu können.
Es gibt noch viel Arbeit, um die Iteration fortzusetzen. Wir wissen, dass die Header-Felder von HTTP2/gRPC komprimiert sind. Derzeit unterstützen wir das Parsing von Protokoll-Headern basierend auf statischen Komprimierungstabellen. In Zukunft werden wir eBPF uprobe verwenden, um dynamische Komprimierungstabellen für das vollständige Header-Parsing zu erhalten. Für HTTPS unterstützen wir derzeit die Fähigkeit von eBPF uprobe, Golang-Anwendungen zu sammeln, und werden in Zukunft schrittweise C/C++/Java/Python und andere Sprachen unterstützen. Gleichzeitig verstehen wir auch, dass es in der tatsächlichen Geschäftsumgebung eine große Anzahl privater Anwendungsprotokolle geben wird, und wir hoffen, Entwicklern durch die WebAssembly-Technologie eine flexible Programmierbarkeit bieten zu können.
Aber diese Indikatoren allein sind nicht perfekt, und die Beobachtbarkeit erfordert so viele Daten wie möglich. Als Nächstes stellen wir die automatisierten Funktionen zur Integration von Indikatordaten von DeepFlow vor.
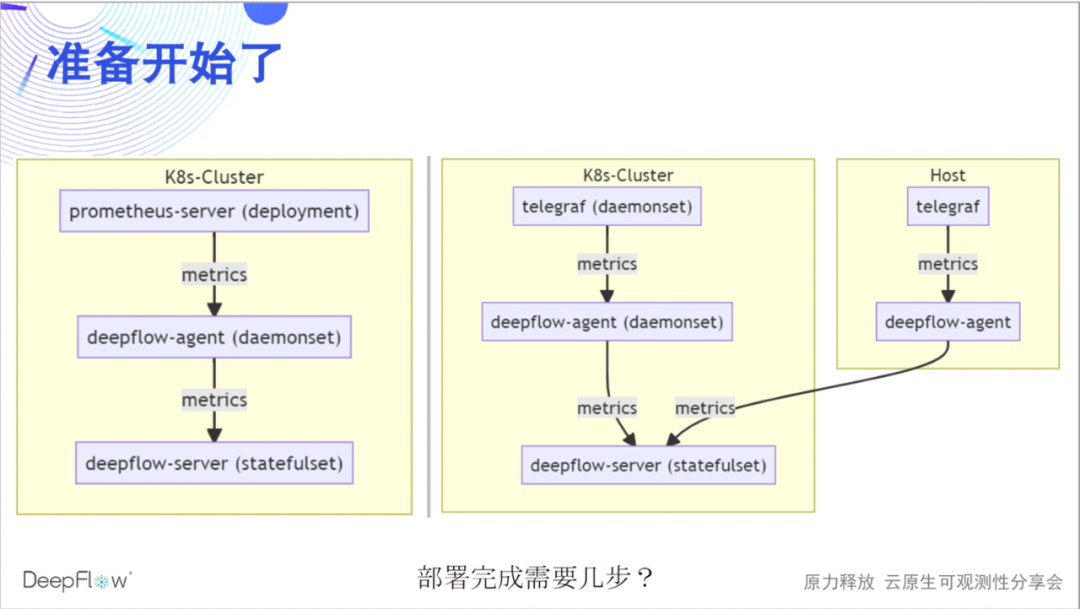
Die folgende Abbildung zeigt die Integrationsmethode von DeepFlow, Prometheus und Telegraf. Wir integrieren Daten über deepflow-agent als Remote-Storage-Endpunkt von Prometheus-Server oder als Ausgabe-Endpunkt von Telegraf. Der gesamte Prozess ist relativ einfach. Glauben Sie, dass es ein paar Schritte braucht, um eine solche Bereitstellung abzuschließen?
Es sind nur zwei Schritte erforderlich, um eine Konfiguration auf der Prometheus/Telegraf- bzw. Deepflow-Agent-Seite zu ändern. Die Konfiguration auf dieser Seite von DeepFlow ist eigentlich nur ein Schalter. Wir schalten ihn standardmäßig nicht ein. Wir erwarten, dass deepflow-agent standardmäßig keine Ports abhört und keinen Eingriff in die laufende Umgebung hat.
# prometheus-server config remote_write: - url: http: # telegraf config [[outputs.http]] url = "http://${DEEPFLOW_AGENT_SVC}/api/v1/telegraf" data_format = "influx" # deepflow config vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1
Eine solch einfache Konfiguration kann auch in verschiedenen komplexen Szenarien ausprobiert werden, die mehrere K8s-Cluster und Cloud-Server abdecken, und kann ohne die Unterstützung externer Komponenten horizontal skaliert werden.
Warum Daten in DeepFlow sammeln Lassen Sie uns zuerst die leistungsstarken AutoTagging-Funktionen erleben. Wir fügen automatisch eine große Anzahl von Tags in alle nativen und integrierten Daten von DeepFlow ein, sodass es keine Hindernisse für die Datenzuordnung und keine Fehler beim Daten-Drilldown gibt. Diese Tags stammen aus Cloud-Ressourcen, K8s-Ressourcen und benutzerdefinierten K8s-Labels. Ich glaube, dass Entwickler diese Fähigkeit sehr mögen müssen, und sie müssen nicht mehr viele verstreute Tags in den Geschäftscode einfügen. Wir empfehlen, dass Sie alle Labels, die angepasst werden müssen, über K8s Label einfügen, wenn der Dienst online geht, vollständig vom Geschäftscode entkoppelt. Was die dynamischen Tags betrifft, die sich auf das Geschäft beziehen, wird DeepFlow ebenfalls vollständig auf sehr effiziente Weise gespeichert, um den Abruf und die Aggregation zu unterstützen.
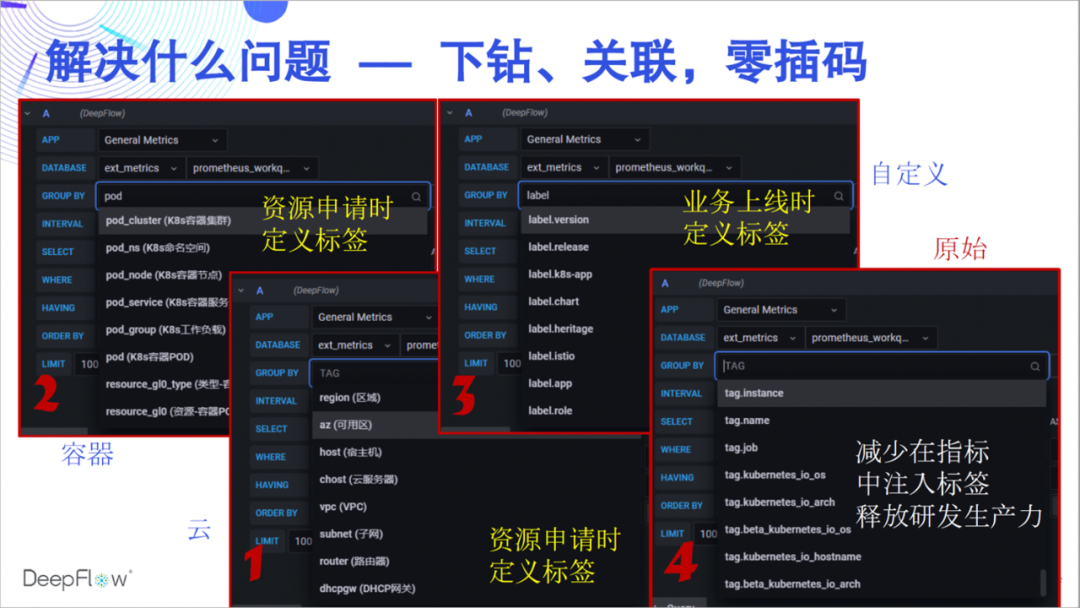 So viele Tags automatisch einfügen, was ist mit dem Ressourcenverbrauch? Der SmartEncoding- Mechanismus von DeepFlow löst dieses Problem sehr gut: Wir codieren die Labels vorab numerisch, die Indikatordaten werden diese Labels während der Generierung und Übertragung nicht tragen, und nur die codierten numerischen Labelfelder werden vor der Speicherung einheitlich eingefügt. Für das benutzerdefinierte K8-Label speichern wir es nicht einmal mit den Indikatordaten, sondern verknüpfen es nur zum Zeitpunkt der Abfrage. Verglichen mit der LowCard von ClickHouse oder dem direkten Speichern von Tag-Feldern ermöglicht uns der SmartEncoding-Mechanismus, die Rechenleistung und den Speicherverbrauch um bis zu eine Größenordnung zu reduzieren.
So viele Tags automatisch einfügen, was ist mit dem Ressourcenverbrauch? Der SmartEncoding- Mechanismus von DeepFlow löst dieses Problem sehr gut: Wir codieren die Labels vorab numerisch, die Indikatordaten werden diese Labels während der Generierung und Übertragung nicht tragen, und nur die codierten numerischen Labelfelder werden vor der Speicherung einheitlich eingefügt. Für das benutzerdefinierte K8-Label speichern wir es nicht einmal mit den Indikatordaten, sondern verknüpfen es nur zum Zeitpunkt der Abfrage. Verglichen mit der LowCard von ClickHouse oder dem direkten Speichern von Tag-Feldern ermöglicht uns der SmartEncoding-Mechanismus, die Rechenleistung und den Speicherverbrauch um bis zu eine Größenordnung zu reduzieren.
Daher ist die Weigerung, Tags in den Geschäftscode einzufügen, nicht nur faul, sondern auch umweltfreundlich.
Was wir mehr wollen, ist die Teamzusammenarbeit durch umfassende Datenintegration und -korrelation zu aktivieren. DeepFlow verfügt über automatisierte Netzwerk- und Anwendungsindikatoren, Prometheus/Telegraf über automatisierte Systemleistungsindikatoren sowie Geschäftsindikatoren, die von Entwicklern über Exporter/StatsD angezeigt werden. Wir hinterlegen diese reichhaltigen Indikatoren in einer Datenplattform und führen eine effiziente automatische Korrelation durch, in der Hoffnung, die gegenseitige Zusammenarbeit von Betriebs- und Wartungs-, Entwicklungs- und Betriebsteams zu fördern und die Arbeitseffizienz aller Teams zu gewährleisten.
Wir haben auch einige geplante Arbeiten zur Metrikintegration. Wir werden die Prometheus remote_read-Schnittstelle weiterhin unterstützen, sodass DeepFlow als vollständiger Prometheus-Remote-Speicher verwendet werden kann, was die Nutzungsgewohnheiten der Prometheus-Benutzer nicht ändern wird. Wir planen, die automatisierten Indikatoren von DeepFlow auf den Prometheus-Server zu exportieren, damit Entwicklungsteams, die mit Prometheus vertraut sind, problemlos leistungsstärkere Panorama- und Full-Stack-Indikatorwarnfunktionen erhalten können. Wir unterstützen auch weiterhin die Integration anderer Agenten und sind der festen Überzeugung, dass Observability in der Lage sein muss, Daten auf breiter Basis zu sammeln. Darüber hinaus unterstützt DeepFlow auch die Synchronisierung von Informationen in der Dienstregistrierung, sodass die reichhaltigen Informationen der Anwendungslaufzeit automatisch als Tags in die Beobachtungsdaten eingefügt werden können.
Jetzt steigen wir in ein neues Thema ein - Tracking. Lassen Sie uns zunächst die AutoTracing-Funktionen der DeepFlow-Automatisierung testen.
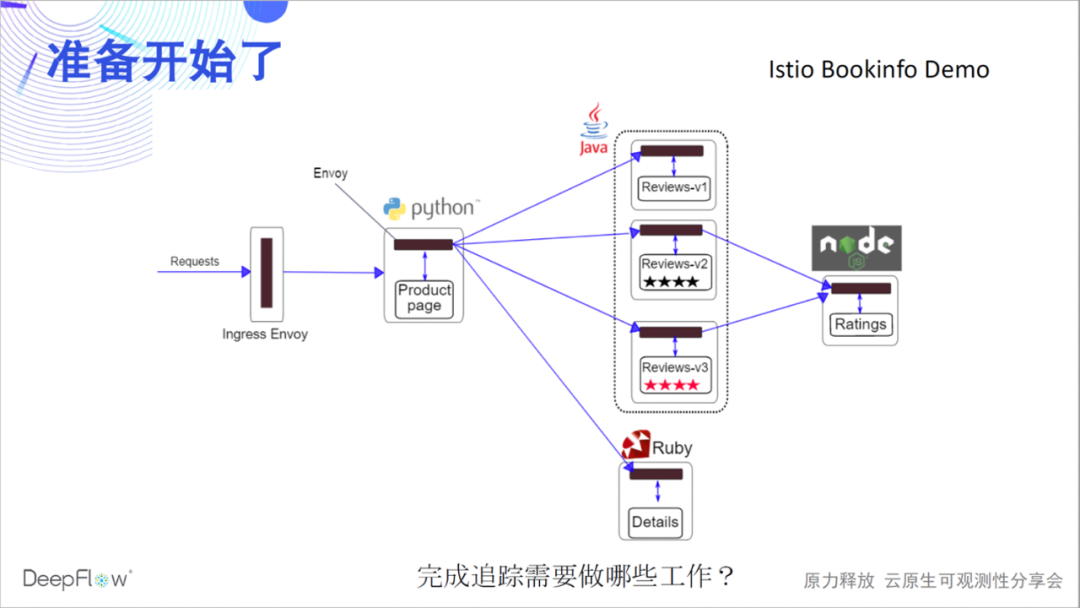
Nehmen wir als Beispiel eine offizielle Bookinfo-Demo von Istio, um das Wunder mit Ihnen zu erleben. Diese Demo dürfte vielen Freunden bekannt sein, es gibt 4 Microservices in verschiedenen Sprachen und Envoy Sidecar. Lassen Sie uns zunächst raten, was wir tun müssen, um die verteilte Ablaufverfolgung abzuschließen?
Werfen wir einen Blick darauf, wie OpenTelemetry +
Jaeger die Demo verfolgt. Sie haben richtig gelesen, denn es gibt keine Instrumentierung in diesem Demo, Jaeger kann nichts sehen, es ist leer.
Was muss DeepFlow also tun? Tatsächlich muss nichts getan werden, da wir DeepFlow bereits frühzeitig über einen Steuerbefehl bereitgestellt haben und keine weiteren Vorgänge erforderlich sind. Es ist Zeit, Zeuge des Wunders zu werden. Ohne eingefügten Code haben wir die Aufrufe zwischen diesen vier Microservices vollständig nachverfolgt. Verlassen Sie sich voll automatisiert auf eBPF- und BPF-Funktionen!
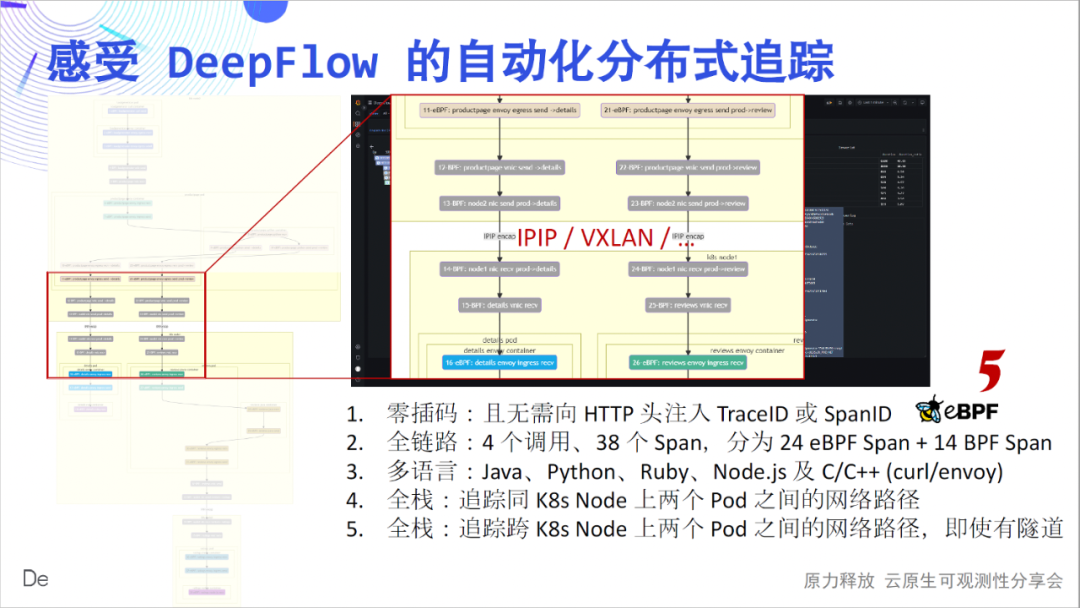
Als nächstes werden wir Sie dazu bringen, den tiefgründigen Charme dieser einfachen Flammenkarte im Detail zu erleben: Zero Insertion ist das erste Gefühl, das wir vermitteln möchten. Wenn wir jede Spanne des Flammendiagramms als Knoten zeichnen, erhalten wir ein Anrufflussdiagramm, aus dem wir den komplexen Anrufprozess dieser einfachen Anwendung klar erkennen können. Der vollständige Link ist das zweite Gefühl, das wir vermitteln möchten. In 4 Aufrufen haben wir 24 eBPF-Spans, 14 BPF-Spans verfolgt und ihre Beziehungen konstruiert.
Mehrsprachigkeit ist das dritte Gefühl, das wir vermitteln wollen. Die von Java, Python, Ruby, Node.js, C und C++ implementierten Dienste werden hier behandelt, und DeepFlow wird stillschweigend verfolgt. Full Stack ist das vierte Gefühl, das wir vermitteln möchten. Wir können sehen, dass der Hop-by-Hop-Netzwerkzugriffspfad zwischen Pods klar ist und wo der Engpass liegt.
Der vollständige Stack wird auch auf containerübergreifenden Knoten widergespiegelt.Ob der zwischengeschaltete Netzwerkpfad IPIP- oder VXLAN-Tunnelkapselung ist, er kannstabil verfolgt werden.
Der vollständige Stack spiegelt sich auch im Datenverkehrspfad innerhalb des Pods wider. Stecken Sie bei der Verwendung von Envoy in einem Labyrinth von Verkehrswegen fest? DeepFlow kann die Blackbox des Strömungswegs im Inneren des Pods leicht öffnen und deutlich sehen.
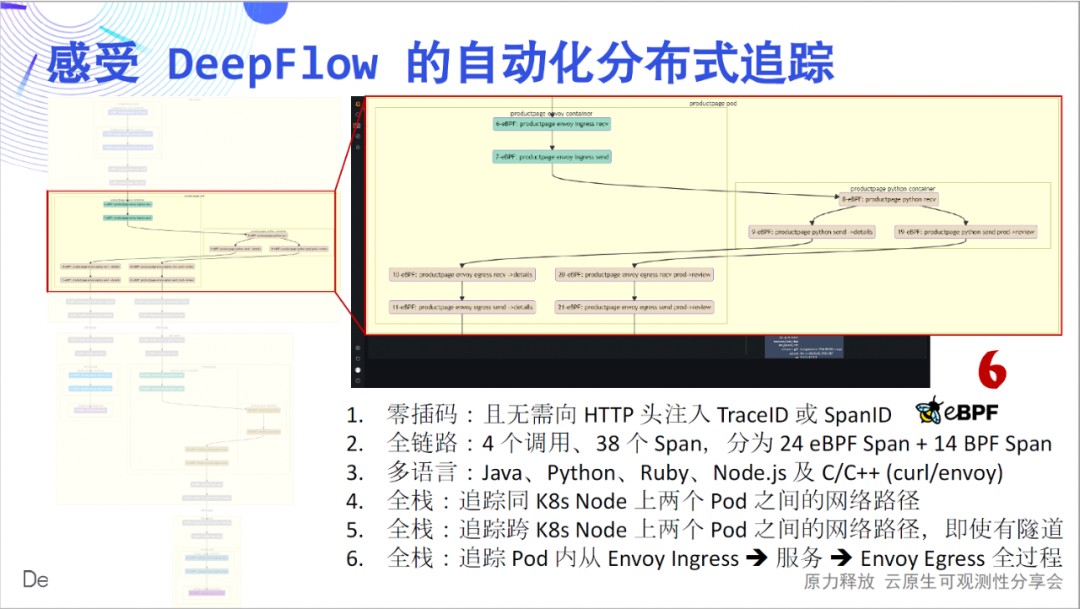
Wenn ich auf die oben genannten sechs Punkte zurückblicke, glaube ich, dass sie alle sehr coole Innovationen sind, und ich glaube, dass jeder dasselbe glauben wird. Diese Demo ist auch in unserer Dokumentation ausführlich beschrieben , herzlich willkommen, sie zu erleben.
Da es sich um eine innovative Arbeit handelt, besteht eine hohe Wahrscheinlichkeit, dass es in der Anfangsphase einige Mängel gibt. Derzeit konnten wir das automatische Tracking in blockierenden IO-Szenarien (BIO) sowie das automatische Tracking der meisten Load-Balancing- und API-Gateways (Nginx, HAProxy, Envoy usw.), die häufig nicht- Blockieren von synchronem IO (NIO). Allerdings sind noch nicht alle asynchronen IO (AIO)-Szenarien wie Lightweight-Threads, Coroutinen etc. gelöst. Unsere Arbeit ist noch im Gange, und es gab einige gute Fortschritte. Wir planen, Ihnen auf der QCon 2022 die Demontage tiefer technischer Prinzipien mitzuteilen .
AutoTracing ist gut, aber es ist schwierig, die Verfolgung von Aufrufen zwischen bestimmten Funktionen innerhalb der Anwendung zu lösen. Glücklicherweise hat die gesamte Open-Source-Community in dieser Hinsicht mehr als 10 Jahre gesammelt, angefangen von der Gründung von Google Dapper vor 12 Jahren über die Popularität von SkyWalking bis hin zum einheitlichen Standard von OpenTelemetry heute. Welche Art von Kombination kann DeepFlow also mit ihnen haben?
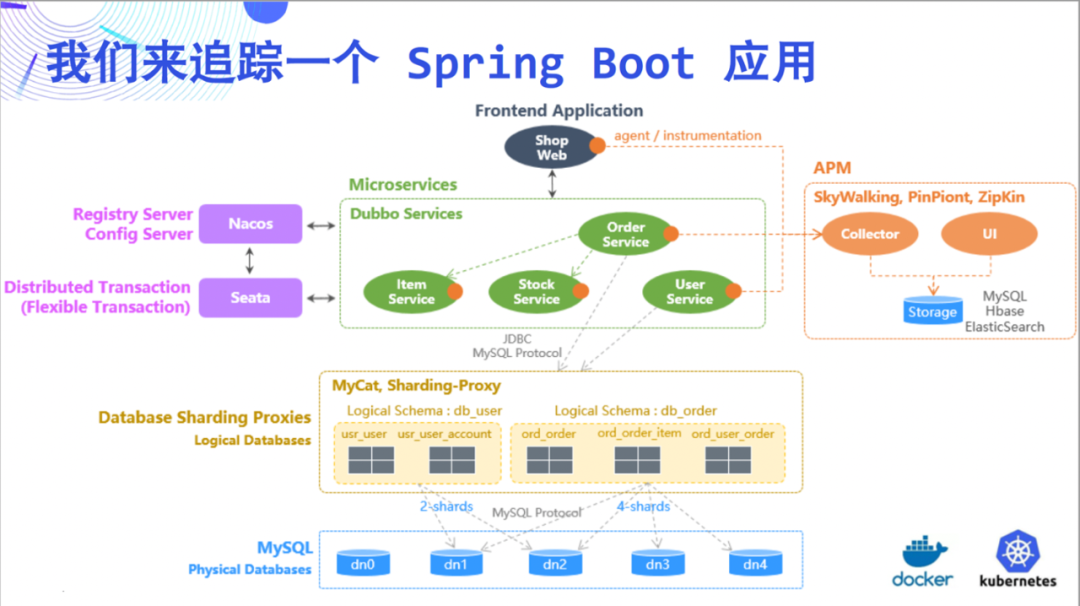
Dieses Mal versuchen wir, eine Spring
Boot-Anwendung als Beispiel zu verfolgen, um die erstaunlichen Fähigkeiten von DeepFlow zu veranschaulichen. Diese Demo ist relativ einfach und besteht aus 5 Microservices und MySQL.
Werfen wir zunächst einen Blick auf den
Tracking-Effekt von OpenTelemetry + Jaeger, diesmal ist er nicht leer, es werden 46 Spans auf der Seite angezeigt.
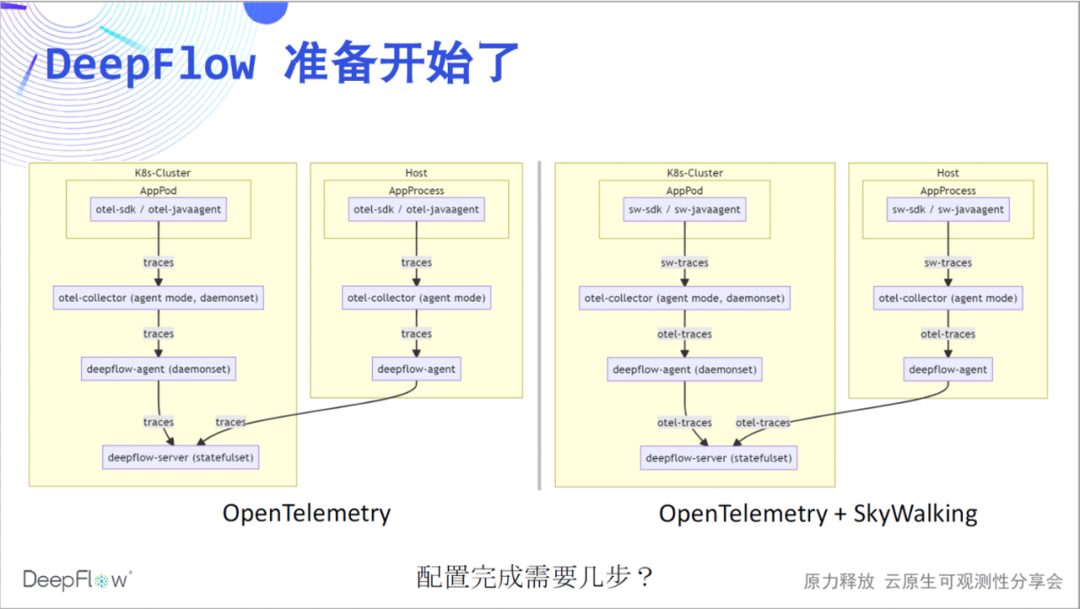
Beginnen wir mit der Leistung von DeepFlow. Wir empfehlen, den Agentenmodus von otel-collector zu verwenden, um Traces über deepflow-agent an deepflow-server zu senden. Ebenso wird die Integration von SkyWalking-Daten derzeit über den otel-collector realisiert. Sie können jetzt erraten, wie viele Schritte wir benötigen, um unsere Konfigurationsarbeiten abzuschließen?
Da die Live-Übertragung bisher durchgeführt wurde, glaube ich, dass es keine Spannung gibt. Wir können in zwei Schritten durch OpenTelemetry und DeepFlow kommen.
otlphttp: traces_endpoint: "http://${HOST_IP}:38086/api/v1/otel/trace" tls: insecure: true retry_on_failure: enabled: true vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # 默认关闭,零端口监听
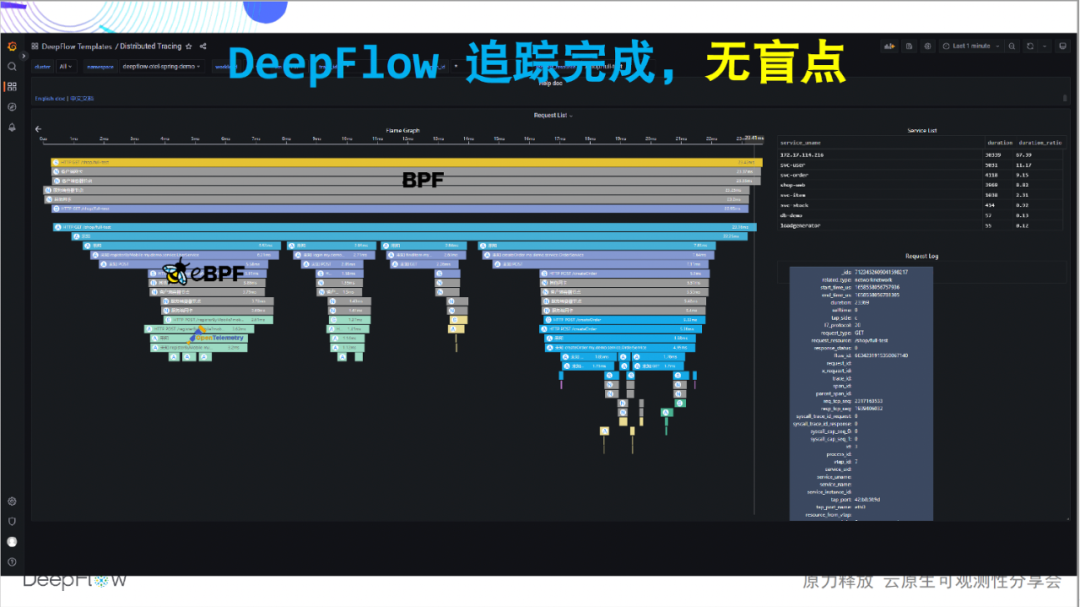
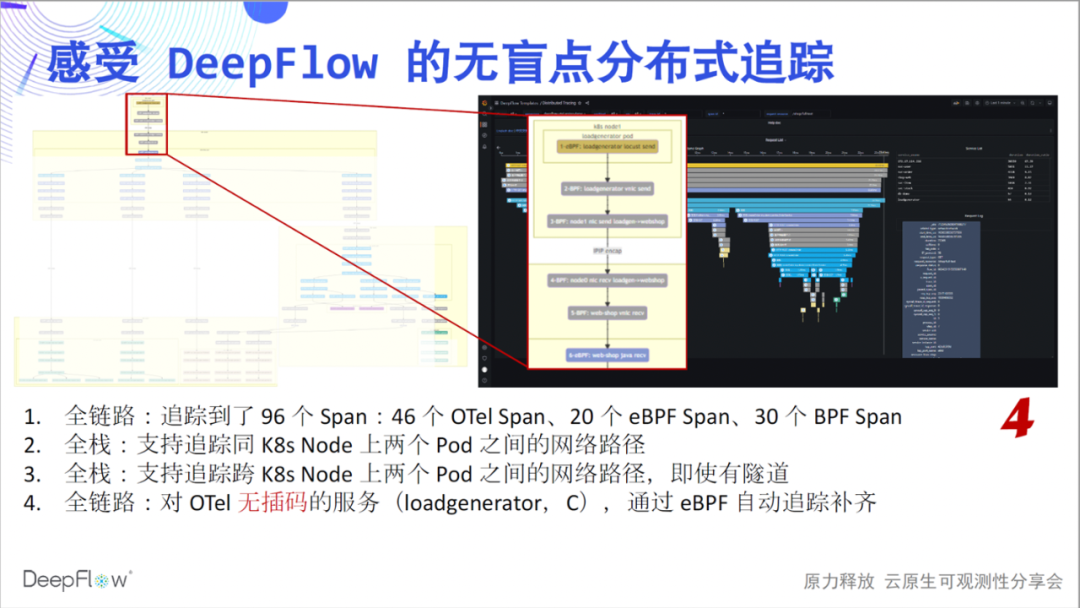
Werfen wir also einen Blick auf die integrierten Tracking-Funktionen von DeepFlow. Dieses Flammendiagramm sieht jetzt flach aus, aber es birgt ein verborgenes Geheimnis. Lassen Sie uns langsam seinen mysteriösen Schleier aufdecken und den Schock des Trackings ohne blinde Flecken spüren: vollständiger Link, Es ist das erste Gefühl, das wir wollen zu vermitteln. Verglichen mit den 46 von Jaeger gezeigten Spans verfolgte DeepFlow zusätzlich 20 eBPF-Spans und 30 BPF-
Spans. Wir haben zunächst ein Zahlengefühl und werden uns Schicht für Schicht weitere Geheimnisse anschauen.
Full Stack ist das zweite Gefühl, das wir vermitteln wollen. Unsere Fähigkeit zur Verfolgung von Netzwerkpfaden ist immer noch stabil und zeigt die Zugriffspfade zwischen Pods deutlich an. Auch im Cross-Node-Communication-Szenario wird zu diesem Zeitpunkt der volle Stack angezeigt, egal ob Tunnel-Encapsulation oder nicht, egal welches Tunnel-Protokoll verwendet wird.
Den ganzen Link möchten wir gerne weiter kommunizieren. Schauen Sie sich die 6 Spannweiten oben im Bild genauer an. Dies liegt daran, dass der Loadgenerator-Dienst keine Interpolation durchführt und OpenTelemetry seinen Tracking-Pfad nicht angeben kann, aber mit der Tracking-Fähigkeit von DeepFlow werden 6 eBPF- und BPF-Spans automatisch gefüllt, und es besteht keine Notwendigkeit, während des gesamten Prozesses etwas manuell zu tun.
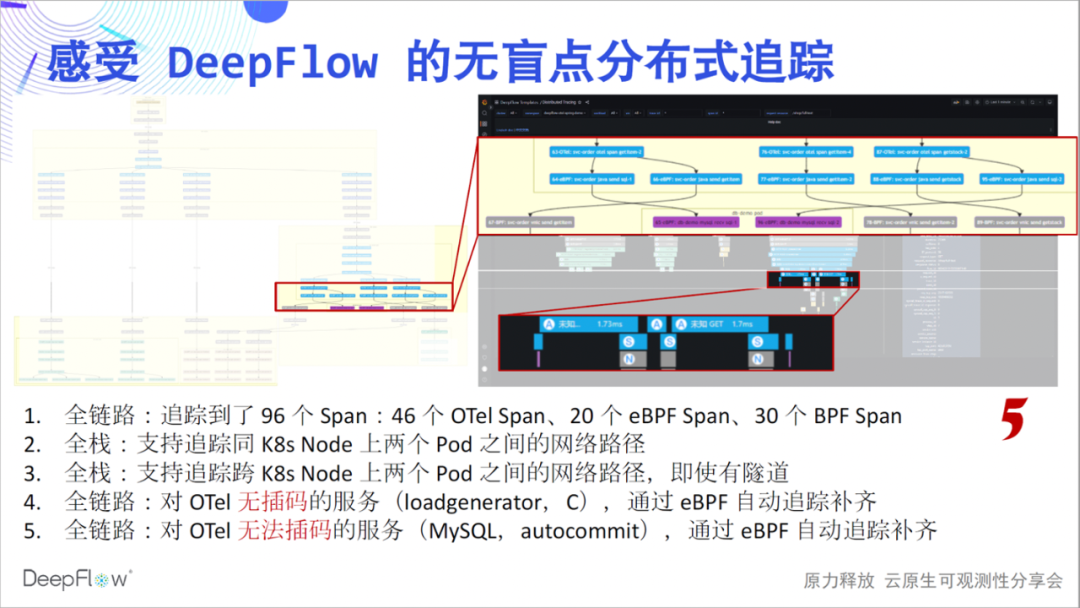
Vollständiger Link, wir möchten weiterhin kommunizieren. Wenn Sie sich diesen Teil der Spanne in der Abbildung ansehen, hat eBPF automatisch zwei Sätze von eBPF-Spans vor und nach einer Reihe von OTel-Spans gefunden, die den Anfang und das Ende von MySQL-Transaktionen darstellen, was sehr cool ist. Ich habe mich gefragt, welche Art von Feedback wir vor Ort erhalten würden, wenn wir diese Funktionen durch Offline-Aktivitäten mit Ihnen teilen könnten, wenn es keine Epidemie gäbe.
无盲点,是我们想传达出来的第六个感受。我们看图中这段 Span,第一行的客户端调用和最后一行的服务端响应出现了显著的时差。这个时候一般上下游团队会去争吵,到底是谁的问题。DeepFlow 就像一个裁判,谈笑间回答了这里面的玄机。从图中我们能看到,靠近客户端的位置虽然 OpenTelemetry Span 的时延大,但 eBPF Span 时延明显降低了,云原生环境不再是一个黑盒,看的一清二楚。我相信大家此时应该也能感受到满满的团队协作感,再也不用争吵了。
我们的文档中也对这个 Demo 进行了详细介绍,欢迎上手体验。另一方面,我们的 AutoTagging 能力也适用于追踪数据,我们会为所有的 Span 自动注入了大量标签。我们不再需要配置过多的 otel-collector
processor 用于标签注入了,一切都是自动的、高性能的、环保的。
那么 SkyWalking 呢。目前我们可以三步配置解决 SkyWalking 数据的集成,虽然多了一步,但相信对比上面的震撼,大家不会认为很麻烦。欢迎参考我们的文档上手体验。
receivers: skywalking: protocols: grpc: endpoint: 0.0.0.0:11800 http: endpoint: 0.0.0.0:12800 service: pipelines: traces: receivers: [skywalking] spec: ports: - name: sw-http port: 12800 protocol: TCP targetPort: 12800 - name: sw-grpc port: 11800 protocol: TCP targetPort: 11800 vtap_group_id: <your-agent-group-id> external_agent_http_proxy_enabled: 1 # required
同样,我们的多集群、异构环境监控能力在追踪场景下仍然是就绪的,整个数据平台仍然不需要外部组件就能水平扩展。
是的,我们也依然还有一系列未来的工作。包括不经过 otel-collector 直接集成 SkyWalking 数据,包括集成 Sentry 数据以解锁 RUM 能力。目前我们的追踪数据通过自己实现的 Grafana Panel 来展现,我想对接 Tempo 应该是一个不错的主意。
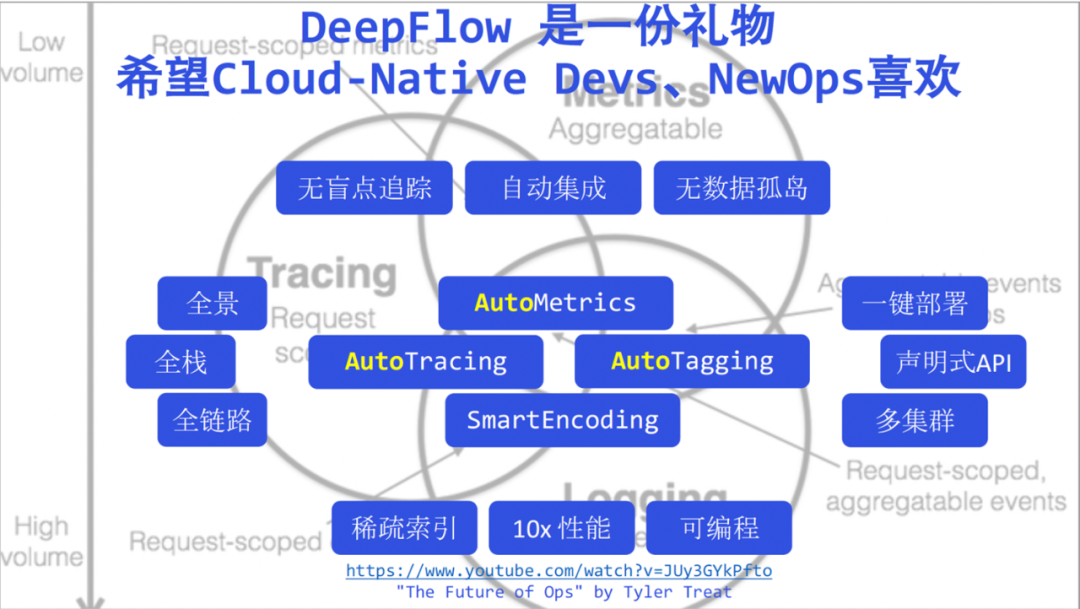
Abschließend stapeln wir als Rückblick die heute erwähnten DeepFlow-Keywords, wobei ich diese schwachen Keywords hier nicht einzeln hervorheben werde. Jetzt sage ich, dass DeepFlow die Observability in eine neue Ära der Hochautomatisierung gebracht hat, ich glaube, Sie werden keine Zweifel mehr haben. Wir glauben, dass DeepFlow ein Geschenk an Entwickler und Betreiber in der neuen Ära ist.
Wir hoffen, dass Entwickler mehr Zeit haben, sich auf das Geschäft zu konzentrieren, dem automatisierten DeepFlow mehr Beobachtbarkeit zu verleihen und ihren Code sauberer und aufgeräumter zu gestalten. Unter diesem Bild habe ich die Rede von Tyler Treat – The Future of Ops angehängt . Tyler hat vor einigen Jahren die Herausforderungen und Chancen von Ops in der cloudnativen Ära erläutert. Ich werde sie mit den Betriebs- und Wartungsstudenten teilen. Hier zolle ich auch Tribut Tyler, und ich glaube auch, dass DeepFlow in der neuen Ära von Ops gemocht werden kann.
Sie fragen sich vielleicht, warum wir heute nicht über Protokolle gesprochen haben. DeepFlow hat in diesem Bereich einige Arbeit geleistet, war aber schon immer beeindruckt von diesem Bereich. Nächsten Monat werden wir den aktuellen Status und die Pläne von DeepFlow in Bezug auf Protokolle zusammen mit der Cloud-nativen Community und Alibaba Cloud iLogTail vorstellen. Sie sind es willkommen, darauf zu achten.
Wir wollen eine erstklassige Open-Source-Observability-Plattform aufbauen. Es ist noch ein langer Weg, genau wie die Besteigung des Mount Everest. Wenn die aktuelle DeepFlow-Versionsnummer in Höhe übersetzt wird, kann sie genau zwischen Lager 2 und Lager 3 liegen. Wir sehen uns an der Spitze von 8848! Danke euch allen!
【Lesen Sie den Originaltext】
Gehen Sie zur Lageradresse von DeepFlow!